Les ORMs (Object Relationnal Mapping), que l’on appelle également frameworks de mappings objet relationnel ou frameworks de persistence, ont été un sujet important en Java il y a quelques temps avec les EJB, les frameworks open-source et propriétaires, la norme JDO. Depuis deux ou trois ans environ, Hibernate fait l’unanimité et est devenu le standard de facto en terme de framework de persistance dans le monde J2EE.
On s’est donc dit : «ça, c’est fait, le sujet accès aux données est fermé, on peut passer à autre chose. Les bases de données relationnelles, ça ne bouge pas tous les jours (en tout cas au niveau des concepts), donc on est tranquilles».
Erreur ! De nouveaux sujets très intéressants voient le jour pour combler des manques des bases relationnelles : la recherche plein texte. Les recherches SQL pour remonter les données de manière ordonnée sur des critères précis sont très pratiques mais ont leurs limites. En effet, Google et les autres moteurs de recherche ont changé la donne. Les internautes sont désormais habitués à taper directement ce qui les intéresse, et s’attendent à avoir des résultats ordonnées par pertinence prenant en compte les variantes des mots (pluriel, conjugaison, …).
Imaginez que vous recherchez la référence d’un contrat dans votre système commercial. Vous vous souvenez juste qu’il s’agit d’une étude de portails. Vous tapez « étude portail » dans la barre de recherche sur la page d’accueil de votre application et vous avez comme premier résultat la mission que vous cherchiez : « Étude comparative de portails ».
Les usages ont changé et les besoins techniques sont apparus : Pouvoir indexer les contenus métiers dans des moteurs de recherche plein texte et pouvoir les requêter simplement.
En ce qui concerne la recherche plein texte, Lucene est la solution open source Java et n’a pas vraiment de concurrence. Cette solution permet d’indexer aussi bien des documents PDF, OpenOffice ou Office, que des contenus métiers. De plus Lucene est implémentée dans d’autres langages (.Net, C, Ruby, Perl, etc.) ce qui le rend encore plus incontournable.
Il est possible depuis longtemps d’indexer son contenu métier dans Lucene et de garder son contenu structuré dans une base de données relationnelle. Tout le problème est de garder les indexes synchronisés lors de la mises à jour des données. Intégrer cette synchronisation dans le code applicatif serait rébarbatif, alourdirait le code, et serait source d’erreurs. Il faut donc une solution élégante pour gérer l’indexation indépendamment du code métier ou du code d’accès aux données.
Face à ce besoin, des solutions techniques ont vu le jour :
Le module hibernate search sortira prochainement en version 1.0. Il s’appuie sur Lucene pour gérer l’indexation, et permet d’indexer des contenus métier structurés et de faire des recherches en mode plein texte.
La librairie Compass permet elle aussi d’indexer votre modèle de données via Lucene pour ensuite le requêter. Contrairement à Hibernate Search, Compass peut être intégré à différents frameworks ou librairies d’accès aux bases de données (OJB, Hibernate, iBatis). Compass permet de s’intégrer à Spring pour gérer l’indexation sous formes de proxies, dans un mode de programmation orientée aspect (AOP). L’intérêt de cette intégration est le bonne séparation entre code d’enregistrement des données et code de synchronisation de la base d’indexation.
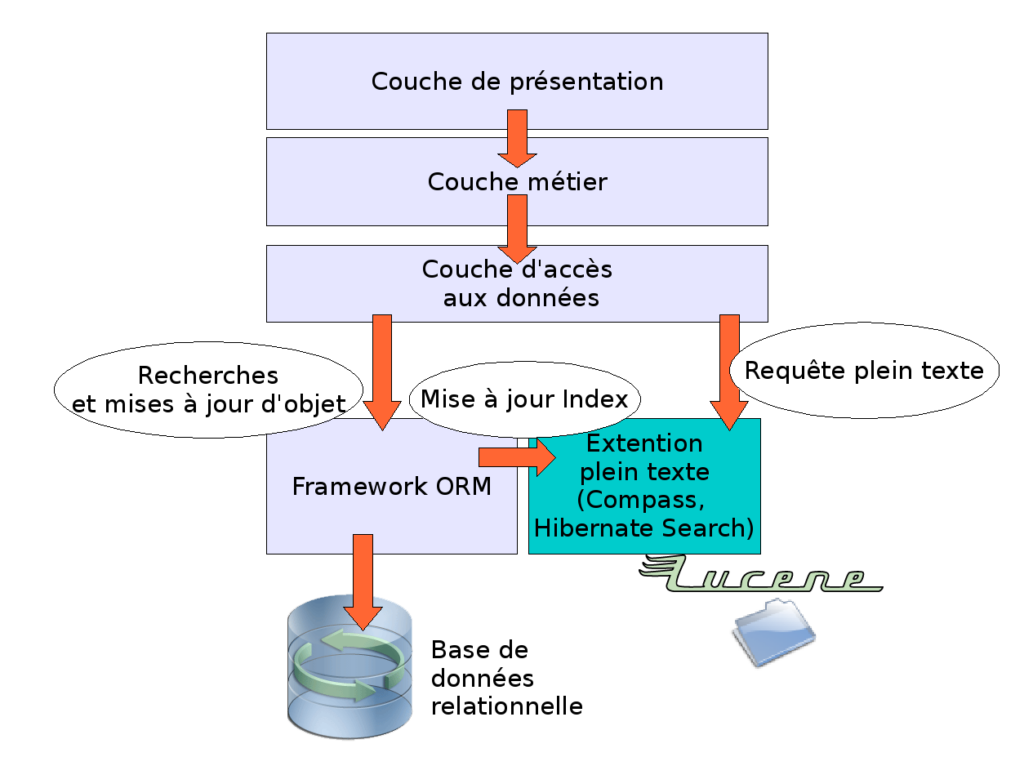
Dans une application en plusieurs couches ces composants s’intègrent entre la couche d’accès aux données et les ORMs.
Ces deux solutions sont encore jeunes, mais elles ont un développement assez dynamique. Elles feront bientôt parties des librairies très utiles pour l’intégration des moteurs de recherche dans les applications ou sites structurés.




