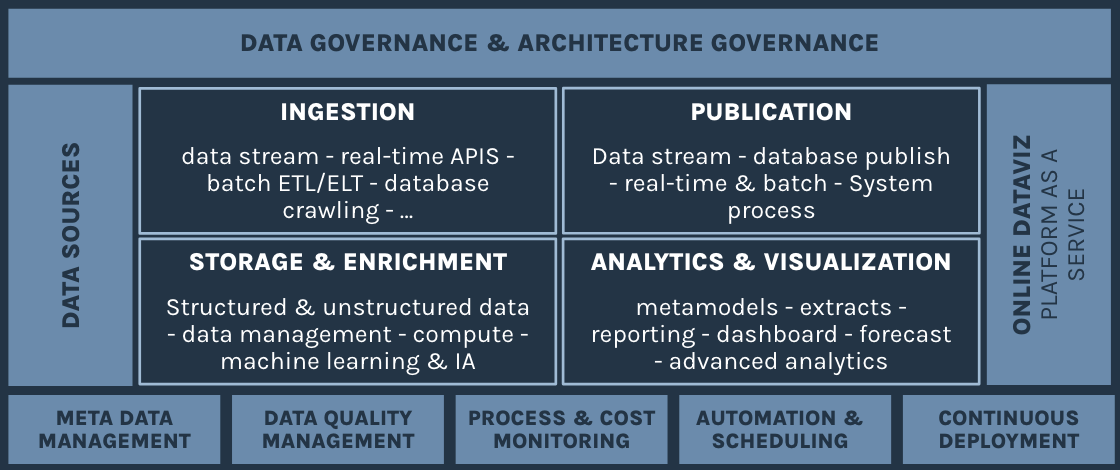
La datavisualisation vise à rendre les données complexes plus compréhensibles et significatives en les présentant de manière visuelle, sous forme de graphiques, de tableaux, de cartes, de diagrammes et d’autres éléments visuels.
Elle a pour objectif :
– une compréhension facilitée des données plus accessibles pour accéléer l’analyse et la prise de décision.
– l’identification des tendances, les corrélation, et les modèles qui pourraient ne pas être apparents dans les données brutes.
– une communication efficace des insights et des résultats aux parties prenantes.
– une exploration interactive pour approfondir les données et de découvrir des insights supplémentaires.
Il existe de nombreuses solutions de visualisation de données, chacune adaptée à des types de données et des objectifs d’analyse spécifiques.
L’activation opérationnelle des données d’une data platform passe de plus en plus par Le « reverse ETL », concept relativement nouveau qui permet de prendre des données qui résident déjà dans une data platform et de les réinjecter dans les systèmes opérationnels ou les applications métier.
Le reverse ETL est devenu pertinent pour permettre de ramener ces données dans leurs applications et systèmes opérationnels pour les utiliser de manière proactive, par exemple pour personnaliser l’expérience utilisateur, alimenter des tableaux de bord en temps réel, déclencher des actions automatisées, etc.