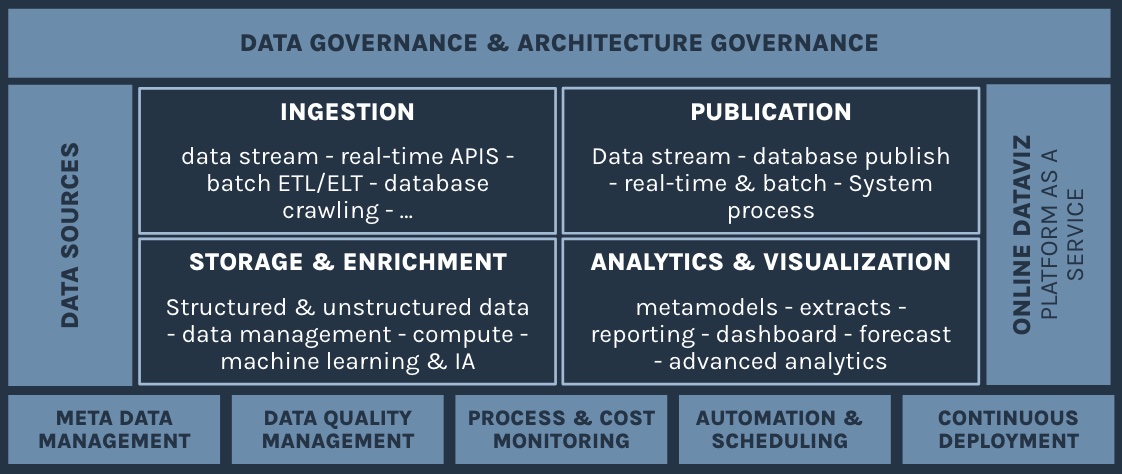
Data governance is a set of processes, policies, and controls to ensure the quality, confidentiality, security, and compliance of data within an organization. This includes actions like defining responsibilities, setting standards and rules, managing access, documenting metadata, data flows management, and more.
When we talk about the combination of data platform and data governance, we refer to the integration of governance practices in the design, implementation and use of the data platform, particularly on the topics of data security, data quality, regulatory compliance and metadata
By integrating data governance into the data platform, the organizations can better control and manage their data, while making the most of its analytical potential. It also helps ensure that data is used responsibly and in compliance with regulatory requirements.