Selon un sondage 2002 organisé par le Delphi Group, la plupart des entreprises manquent considérablement d’organisation pour leur gestion documentaire.
Les résultats de ce sondage annoncent que près de 70% des utilisateurs n’arrivent pas à (re)trouver sur le réseau les informations dont ils ont besoin. Étant dans la nécessité d’exploiter des dossiers, des articles, des documents capitalisés sur leur intranet ou sur le Web, les employés passent près de deux heures par jour à chercher ces informations ; soit environ cinq jours pas mois, et soixante par ans ! Cette perte de temps doit être prise en compte par l’entreprise.
Si les documents sont réutilisés, améliorés chaque jour, les dernières mises à jour disponibles posent souvent un problème de coordination entre les intéressés. De plus, la quantité d’information produite par chaque employé double en moyenne tous les deux ans. La gestion du cycle de vie des documents (archives, versions) crée une quantité de données grandissant de manière exponentielle, ce qui devient vite ingérable si une solution n’est pas mise en place.
En étudiant le travail des documentalistes, on peut retrouver ces méthodes. Les opérations de tri manuel ne sont pas de bonnes solutions pour les grandes entreprises en phase d’expansion. On peut donc se demander quels sont les cheminements à suivre pour aboutir à un système ordonné : comment adapter sa démarche pour trouver un système de classement automatique et de recherche performant, capable de s’adapter à l’activité de l’entreprise ?
Nous verrons qu’il s’agit de réunir l’ensemble des sources de données à étudier, puis de les décrire chacune de manière détaillée. Ces descriptions pourront suivre plusieurs types d’analyse différents, ce qui, selon le métier étudié, permettra une classification intelligente et bien représentative de l’activité de l’entreprise. Il ne restera plus qu’à choisir les interfaces de recherche que l’on souhaite implémenter.
Les sources de données
Avant de s’intéresser aux types de solutions existantes, on doit pouvoir être capable de définir l’univers documentaire que l’on veut exploiter. L’information étant la plupart du temps disséminée sur des disques physiques, dans des bases de données, sur le web (intranet, extranet…), il est nécessaire d’avoir accès à tous ces supports de stockage pour pouvoir prendre en compte la totalité de l’univers. Cette collecte d’information peut poser des soucis, notamment pour la lecture de certains fichiers comme les formulaires HTML, les documents multilingues ou dotés de caractères spécifiques (UTF-8, ISO-8859-15…).
Un utilisateur doit, dans sa démarche, établir la liste de tous les formats documentaires à traiter (PDF, Excel, XML…), mesurer l’espace disque que représente son patrimoine, différencier les types de contenus (journalistique, scientifique, biologique…), établir les permissions qui leur sont accordées (on parle de workflow documentaire), recenser le nombre de langues différentes (française, anglaise, espagnole…) et les jeux de caractères utilisés (ISO, UTF…).
Fort de cet inventaire, on peut mieux définir les bases d’une indexation, et chercher un outil qui répond aux contraintes techniques existantes.
L’indexation et le classement
Définition
L’indexation d’un texte consiste à repérer et extraire certains mots ou expressions particulièrement significatifs (appelés « termes ») dans un contexte donné, et à créer un lien entre ces termes et le texte original.
L’outil de choix sera capable d’attribuer à chaque document des marques distinctives, renseignant avec pertinence sur le contenu, en vue de le classer.
L’indexation distingue généralement les informations sur la structure du document (ou si l’on préfère les « méta données » ; on parle de l’intention du document) des informations de contenu propre à chaque document (l’extension du document). Toutes ces informations constituent ce qu’on appelle une taxinomie : une chaîne composée de valeurs nécessaires et suffisamment significatives pour identifier le document parmi toute une diversité[le terme taxinomie est généralement utilisé dans le contexte de la biologie pour la classification des espèces ; voir par exemple cette [taxinomie des animaux]].

Voici typiquement un problème de content management system (système de gestion de contenu): comment définir la taxinomie de ses documents ? Il faut en premier lieu définir un objet « document » qui porte en lui toutes les caractéristiques des documents du patrimoine :
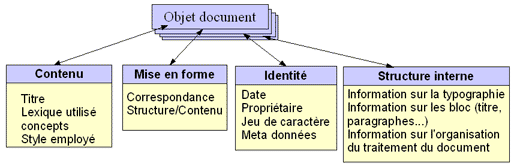
Une taxinomie des documents pourrait donc être organisée selon ces quatre couches descriptives, chacune définissant les propriétés vitales du document. On pourra par la suite lancer des recherches sur tous les attributs de description qui ont servi à l’indexation (recherche par date, propriétaire, langue, titre, plein texte, typographie…).
Le stockage de l’information
On utilise des structures de stockage pour conserver ces informations de classification. Les solutions techniques les plus fréquemment utilisées sont des tables de hachage ou des arbres AVL qui assurent la gestion des données de masse.
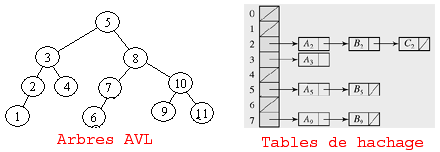
Si la structure d’indexation ne s’équilibre pas, ses catégories seront délocalisées ou noyées dans la masse d’information ; si l’analyse appliquée n’est pas spécialement adaptée aux types de contenus à traiter, des anomalies de sens dans le classement entraineront forcément des surplus d’incohérence ; si les documents sont trop volumineux, les tables d’indexation risquent de devenir presque aussi grandes que le capital lui-même.
On emploie donc de nombreuses techniques de compression, qui réduisent ces bases volumineuses, les rendant plus concises et mieux exploitables :
– stop words : interdire les traitements des mots redondants (la, le, un…) ;
–stemming : réduction des mots par découpage ;
– case folding : rassemblement des mots semblables, mais écrits légèrement différemment ; le but est d’éviter les doublons de valeurs identiques (ex : de gaulle, degaulle, DeGaulle, DEGAULLE…).
De plus, les techniques de logique floue permettent aujourd’hui de conceptualiser un contenu, en « arrondissant » chaque phrase à sa valeur utile. Toujours dans le but d’éviter les erreurs de sens, la phonétisation permet de mener une analyse secondaire uniquement basée sur la sonorité des mots, ce qui réduit les possibilités de sens erroné.
La catégorisation documentaire
L’ensemble étant proprement indexé, il faut alors choisir une méthode pour classer les documents futurs ! Chaque document entrant devra suivre le processus de catégorisation et trouver une place unique dans le classement.
On parlera de catégorisation :
– Manuelle : c’est une solution difficile à mettre en œuvre. Pour un petit patrimoine, cela reste toujours une solution, mais la démarche n’est pas complète.
– Par moteur de règles : typique du modèle efficace, mais vite complexe. L’ordonnancement des règles doit suivre une logique de traitement préétablie, c’est-à-dire un traitement séquentiel afin d’éviter qu’un document ne suive une règle avant une autre. On se retrouve alors face à des soucis de maintenance (ordonnancement) et de modification de ces règles (effet de bord), d’où le besoin de prendre des précautions exemplaires de manipulation, voire de se faire seconder d’une ressource compétente.
– Par apprentissage supervisé : le système nécessite un entraînement. Celui-ci se fait en donnant à l’agent (l’élève) une entrée ainsi que le résultat qui devrait théoriquement être obtenu. L’agent cherchera à minimiser l’erreur en comparant chaque document entrant avec les exemples de référence ; il tentera de se rapprocher de la solution la plus adéquate. Pour affiner le calcul, l’emploi des exemples négatifs permet d’ajouter un concept d’exception.
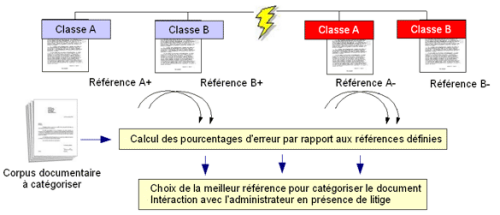
– Par apprentissage automatique : les résultats sont assez encourageants dans le domaine de la construction automatique d’ ontologies [voir à ce sujet une étude sur les [ontologies et l’intéropérabilité ]] par analyse de corpus de textes propres à un domaine. Dans ce cas, le système construit une liste des principaux termes récurrents et tente de les relier en utilisant un dictionnaire ou un glossaire ainsi qu’une base de règles grammaticales (voir par exemple altavista 2.0).
L’étude du contenu se fait par exploitation du texte (text minnig). L’état de l’art aujourd’hui consiste à coupler une analyse linguistique à des algorithmes éprouvés de reconnaissance de forme (SPSS/Lexiquest, SAS/inxight).
Pour assurer la compatibilité, les moteurs d’indexation et de recherche sont souvent couplés (ex : Tropes/Zoom/index d’Acetic); ils peuvent la plupart du temps se greffais sur des applications de gestion répandues (Lotus/IBM, SharePoint/Microsoft). On trouve une grande diversité de choix et la concurrence se fait rude. La lutte se tient entre l’intéropérabilité de logiciels variés qui dialoguent ensemble, ou le choix d’un progiciel de gestion unique.
Conclusion
Dénombrer, rassembler et différencier son univers documentaire permet une indexation globale de ses documents.
Mais cette indexation ne prend pas en compte la valeur sémantique des documents : une phase d’analyse linguistique supplémentaire est nécessaire pour permettre des recherches plus élaborées sur les contenus.
Cette seconde phase fera l’objet de notre prochaine chronique : Organiser sa gestion documentaire (deuxième partie) : Analyse linguistique et recherche.



